Overview
Spring 2012 I did research supervised Dr. Russel Clark from the College of Computing and GTRI at Georgia Institute of Technology in Atlanta GA. A team of 4 graduate students worked to implement an experimental web to mobile service. This conversion exploits industry standards in web development and applies clever algorithms for parsing web content and formatting it to XML. The XML data can be parsed by applications or XSLT scripts can be used to generate mobile specific pages. The group successfully implemented a web service which parses web content and converts the page to an easy to navigate mobile format, including functionality such as handling links and forms.
Background and Technologies Used
 |  | The project originally started as a class project. The goal was to scrape Georgia Tech's course websites (T-Square), extract roster photos from courses and display them using JQuery Mobile. The web scraper was implemented in Java using the JSoup libraries to navigate and parse web content (getting past security was a nightmare!) then submits image links and student info to a PHP 5 server through a public API. When the user visits the PHP server, they must login using Georgia Tech's central login system and will be presented with a lists of available images with courses. This has turned out to be a priceless resource as a teaching assistant of over 500 students in the past 2 years. GT Students and professors you can try it here, hosted on GtMob. |
The current project is aimed to generalize that service to allow easier navigation in a mobile browser. We deployed the project on Google App Engine as a Java application. The Eclipse IDE provides useful developer plugins for App Engine. Git Hub was used a the repository since up to four developers were working on the code at once. The source code is open source and available here along with instructions for setting up the project in the Eclipse IDE. A thousands thanks go out to JSoup developers for their Java HTML-DOM library. It takes in html source and acts similar to JQuery selection, with regex, element, id and class queries available to name a few. Html parsing was done with custom algorithms and data structures. XML was converted with an XSLT script using Java transformation libraries. All information about 3rd party Java libraries can be found in the repository
My Role in The Project
I proposed the project to Dr. Clark after taking his Mobile Applications and Services course in Fall 2011. One of my project group members from the class continued on the project with me working in Dr. Clark's lab. I worked to define the problem and suggested solution, design the software architecture, define the XML syntax and structure, design/implement the parsing algorithms and design the mobile interface and write the XSLT scripts.
Defining the Project and Research Proposal
The original proposal can be found downloaded here. Dr. Clark accepted the project as part of his GTRNOC Lab in GTRI.
Abstract: We intend to develop a Java server application capable of intelligently converting content on a full size web site into a mobile friendly presentation. This will be accomplished using a custom markup implemented with multiple experimental scripts to dictate the behavior of the conversion algorithm. A custom script will be written to generate an optimal display for Georgia Institute of Technology’s T-Square website. A dedicated Java server will use the Jsoup web service library for parsing and conversion of HTML text while Jquery and Jquery-Mobile services will be used in the converted pages for a restful web experience and mobile specific formatting.
Project Architecture
This general architecture diagram shows interactions between various aspects of the application.

The server architecture diagram is an expansion of the JMCS Server Side block. The design allows for development of a public and developer front end for mobile browsing and page parsing service for web applications respectively.

Two consideration are presented below for flow of content parsing and conversion. The diagram on the right allows for an extra step of token replacement in the final HTML code. This was considered to allow for the option of images and content to be kept separate. This would allow for the possibility of faster page loads and only loading images upon user request, lightening the network load and minimizing required data transfer to mobile devices.
 |  |
Click for larger images.
The three images below illustrate our scale-ability problem.
LEFT: representes the ideal situation, a single parsing algorithm, single XML syntax and multiple "skins" or mobile output formats. This assumes that all pages can be parsed with a general algorithm.
CENTER: shows the most an alternate solution allowing specialized parsing algorithms for different sites and page formats e.g. blogs, image galleries, online shopping. Notice the common XML format, which has been a major goal in modularity of the project.
RIGHT: shows the problems with allowing multiple parsing algorithms and XML structures. This forces multiple XSLT scripts to be written for each format, providing an exponential amount of coding to be done. The is conflicting to the goal of this project of providing a simple universal solution for web to mobile conversion.
 |  |  |
The final implementation for the java application can be seen below. Changes to the code have been made since exporting this UML diagram but the general dependencies remain the same.

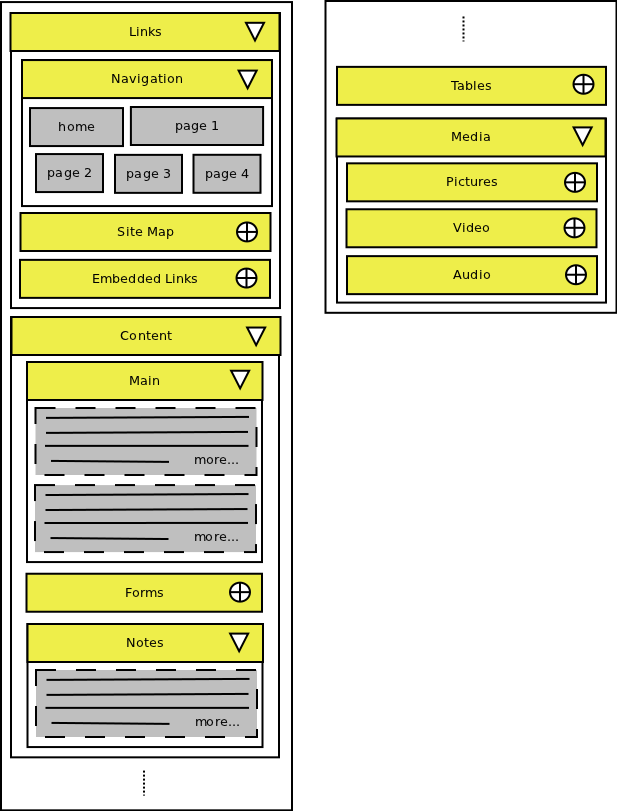
XML Structure and Syntax and Mobile Interface Design
The original proposal can be downloaded here. The final XML structure is defined on the left. A sample "data dump" interface is shown on the right. The details have changed in the final implementation, but the look and feel remain the same.
- html2mobile
- links
- linkgroup
- link
- src
- text
- contentblobs
- content
- text
- form
- code
- media
- images
- picture
- src
- videos
- video
- src
- audio
- sound
- src
Web Content Parsing Algorithms
Parsing Links: This project assumes that spacial relativity is directly correlated with contextual relativity in regards to links on web pages e.g. navigation. Therefore we define a linkgroup as a collection of links with similar immediate or close ancestors in the HTML-DOM tree. Specifically, for each link we search for other links contained in its parent element. If the number of links found was over a certain threshold then a link group was created with those links. If the threshold was not broken then we searched for all links contained in the grandparent element, considering the same linkgroup threshold. This continued up an arbitrary number of levels before declaring that the link is not spacially related to any other links. Experimentally we found relation up to three generations produced the best results. All unrelated links were placed in a final "orphan" linkgroup for display. This orphan linkgroup often contained login/logout links.
Parsing Forms: Rather than writing an extensive library to handle hidden fields and each specific form element, we adopted a simple algorithm which places the original html into the XML document.
Parsing Content: More coming soon...
Parsing Forms: Rather than writing an extensive library to handle hidden fields and each specific form element, we adopted a simple algorithm which places the original html into the XML document.
Parsing Content: More coming soon...
Mobile Interface Design
More coming Soon...
XSLT Scripts
More coming Soon...
Conclusion and Final Report
The final report can be downloaded here. More coming soon...
No comments:
Post a Comment